
Agent S: An Open Agentic Framework that Uses Computers Like a Human
Hey! A few months ago, I gave a talk at Princeton University on my thoughts about agents and Simular. Figured I should put together a summary and turned it into a blog post.
State-of-the-Art Performance
My first job was as a research scientist at Google DeepMind, where a key part of my role involved collaborating with various Google product teams to identify opportunities for applying our cutting-edge AI technology. However, one Googler asked me a totally unrelated question that may have ultimately sparked my decision to leave DeepMind and start Simular.
Agent S is a new agentic
framework designed to enable
computers to be used as
intuitively as a human would
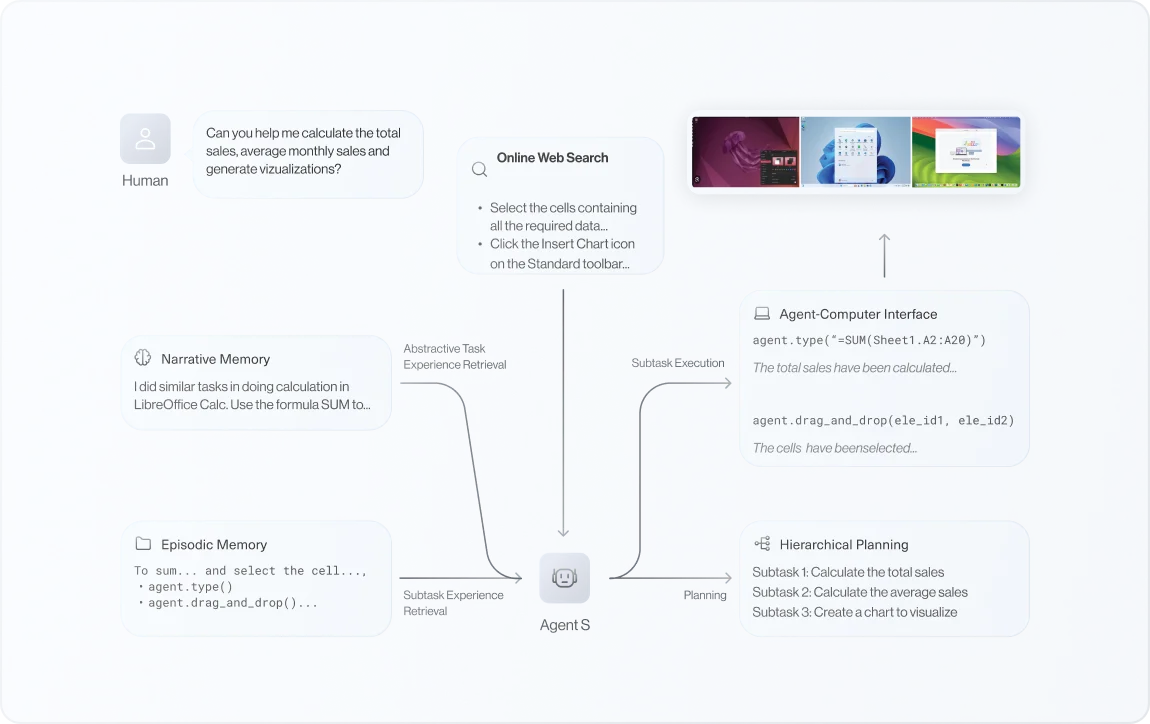
We introduce an Experience-Augmented Hierarchical Planning method. This method utilizes Online Web Knowledge for up-to-date information on frequently changing software and websites, along with Narrative Memory to leverage high-level experiences from past interactions. By breaking complex tasks into manageable subtasks and using Episodic Memory for step-by-step guidance, Agent S continuously refines its actions and learns from experience, achieving adaptable and effective task planning.
Abstract
We present Agent S, an open agentic framework that enables autonomous interaction with computers through Graphical User Interface (GUI), aimed at transforming human-computer interaction by automating complex,multi-step tasks
To this end, Agent S introduces experience-augmented hierarchical planning, which learns from external knowledge search and internal experience retrieval at multiple levels, facilitating efficient task planning and subtask execution.
In addition, it employs an Agent-Computer Interface to better elicit the reasoning and control capabilities of GUI agents based on Multimodal Large Language Models. Evaluation on the OSWorld benchmark shows that Agent S outperforms the baseline by 9.37% on success rate (an 83.6% relative improvement) and achieves a new state-of-the-art. Comprehensive analysis highlights the effectiveness of individual components and provides insights for future improvements.
Furthermore, Agent S demonstrates broad generalizability to different operating systems on a newly-released
WindowsAgentArena benchmark.
Agent S addresses three key challenges in automating computer tasks:

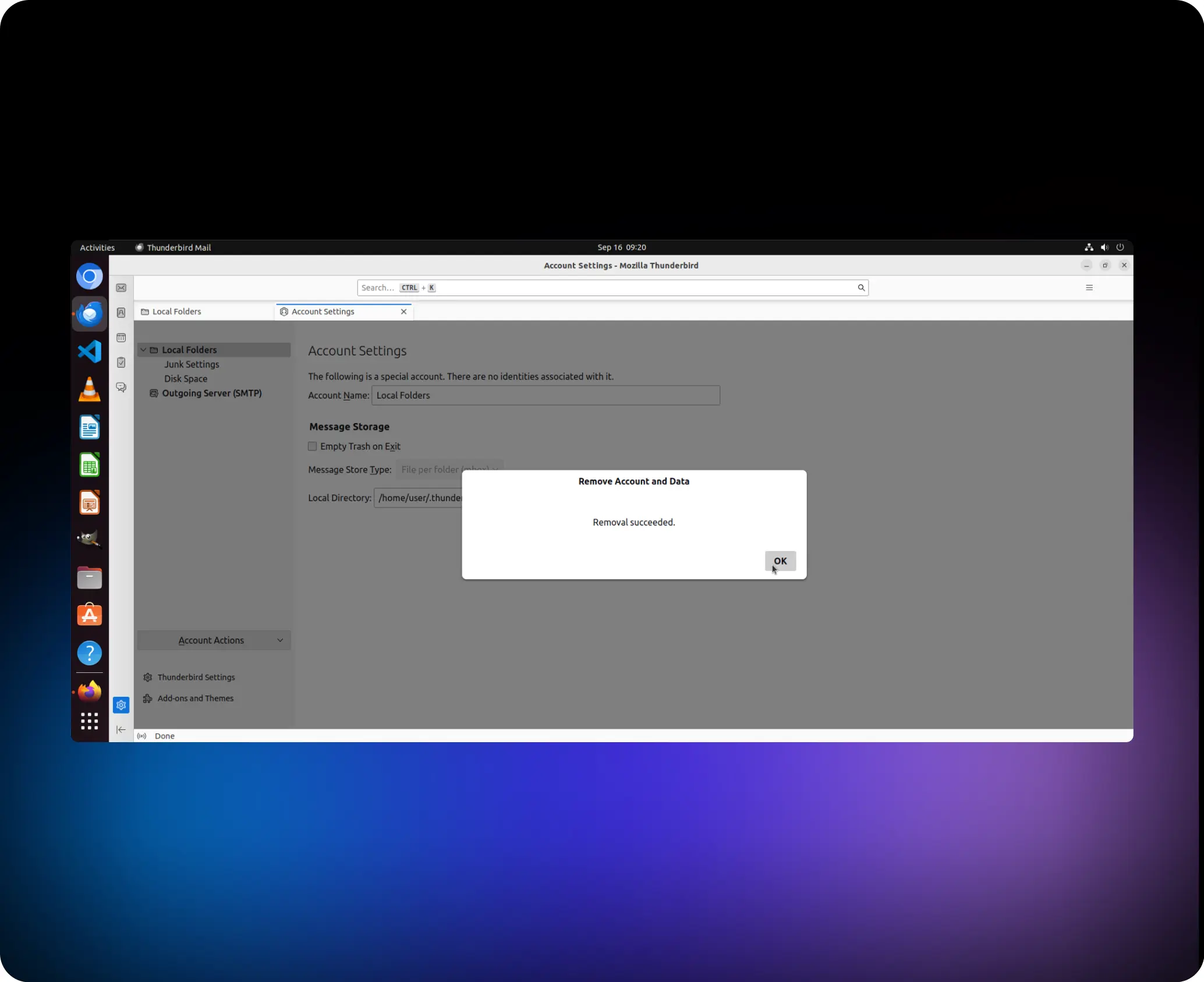
Task Instruction
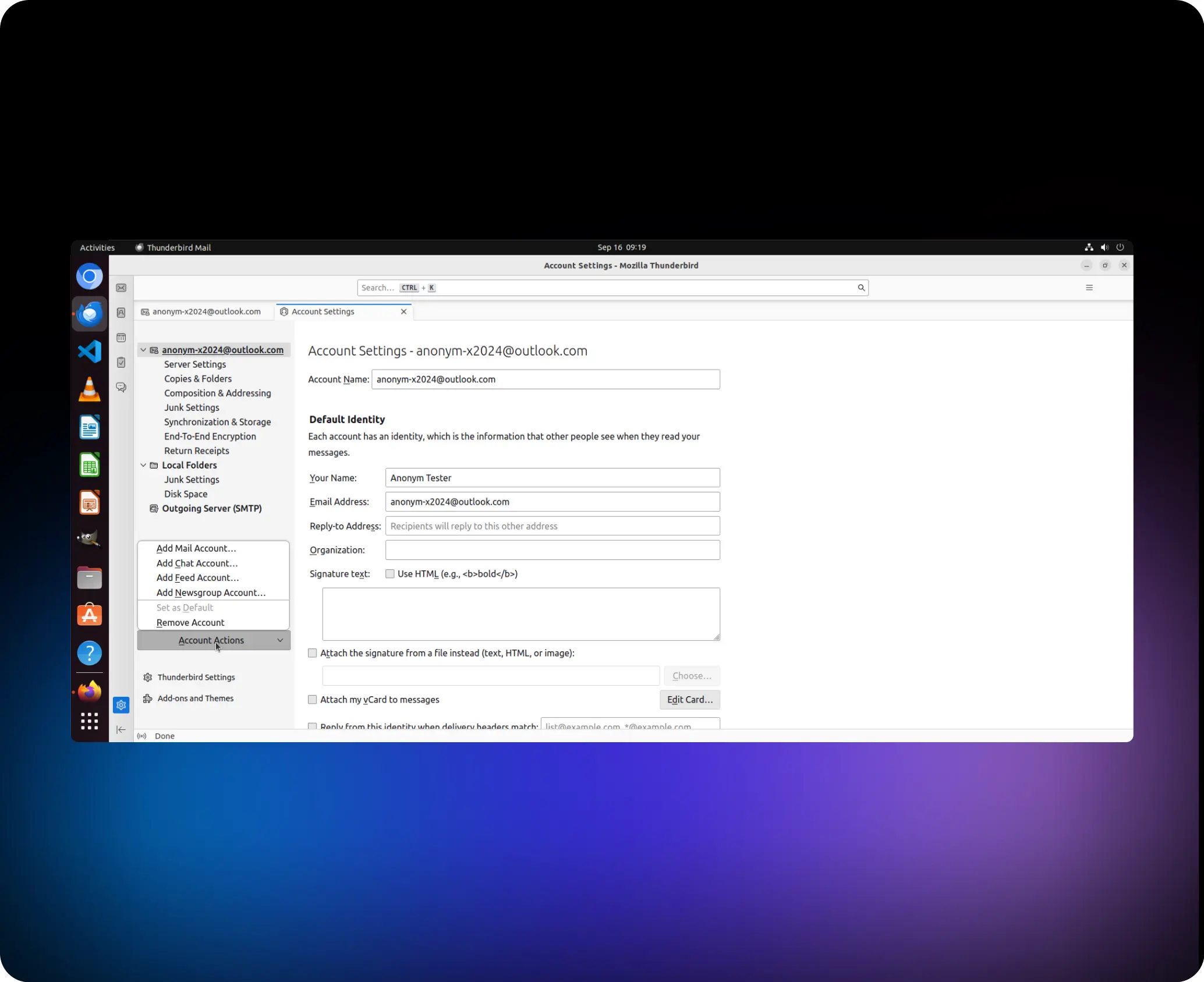
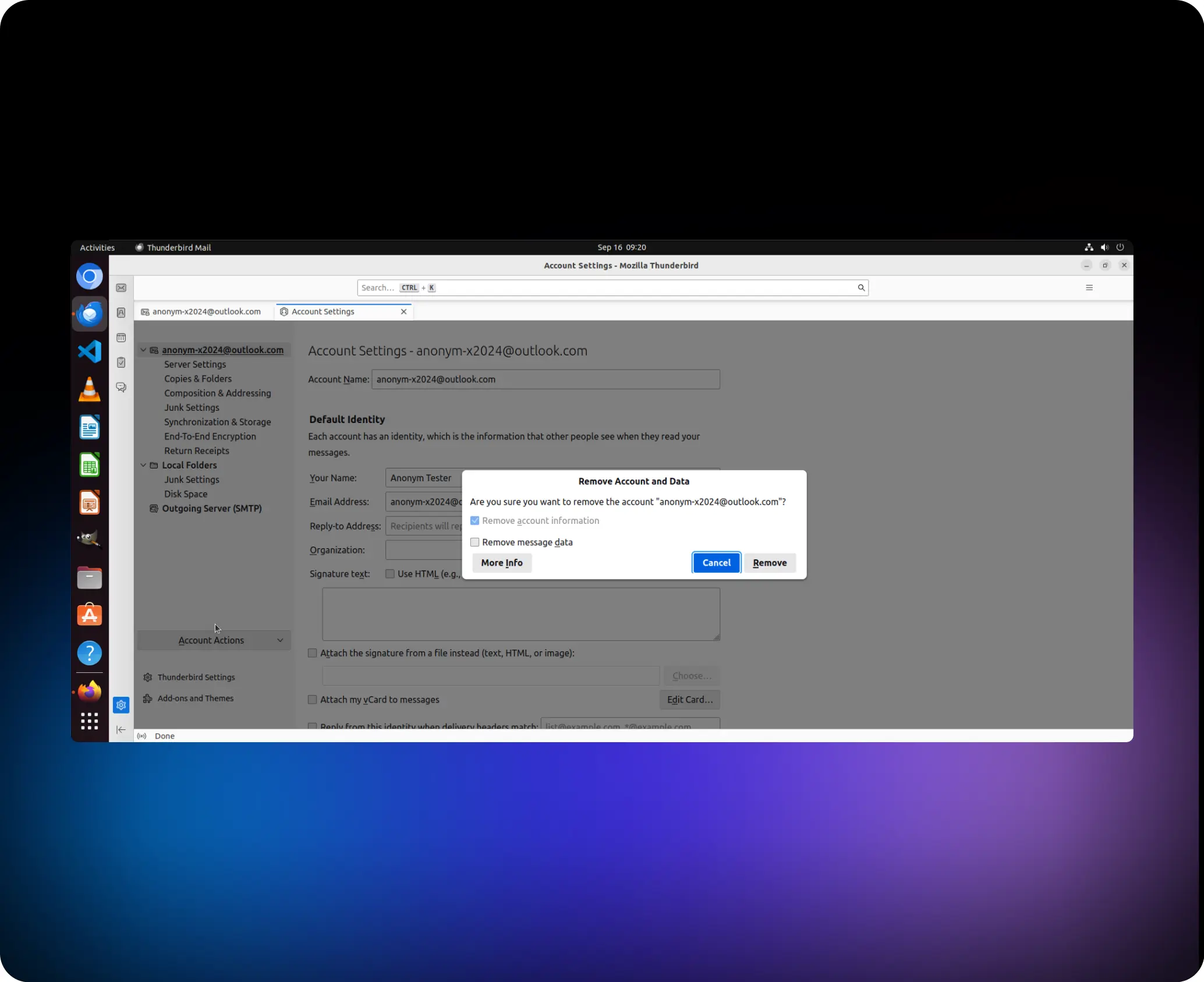
Help me to remove the account “anonym-x2024@outlook.com”
01
agent.click (41,1, “left”)

02
agent.switch_applications (“Thunderbird”)
03
agent.click (95,1, “left”)
04
agent.click (86, 1, “left”)
05
agent.click (93, 1, “left”)
06
agent.click (149, 1, “left”)
.webp)
.webp)
Overview of Agent S Framework
Given task Tu and initial environment observation 0o, the Manager conducts experience-augmented hierarchical planning using web knowledge and narrative memory to produce subtasks So,…,Sn. For each Si, Worker Wi draws from episodic memory to generate an action at at time t, which is executed by the ACI to return the next immediate observation ot+1. A self-evaluation module closes the loop by storing the summarized subtask and full-task trajectories in narrative and episodic memory.
Pipeline of Memory Construction and Update
The pipeline of memory construction and update, which contains two phases: Self-supervised Exploration and Continual Memory Update. The initial Narrative & Episodic Memory is constructed through some randomly curated tasks during the exploration phase, and then it is updated based on the inference tasks continually.
Main Result
This table shows the performance comparison between Agent S and the baseline models, evaluated across the whole OSWorld test set. For the GPT-4o model, Agent S achieves an overall success rate of 20.58%, nearly doubling the performance of the best corresponding baseline (GPT-4o with 11.21%).
Agent S consistently outperforms the baselines in the “Daily” and “Professional” tasks, where it reaches 27.06% and 36.73% success rates, respectively, compared to the best baseline results of 12.33% and 14.29%. These tasks are commonly used in daily life or involved with knowledge-intensive professional applications, which benefit more from the retrieval augmentation of Agent S. Both Claude-3.5-Sonnet and GPT-4o outperform the baseline versions across the majority of tasks. Claude-3.5-Sonnet even performs better than GPT-4o in “Daily” and “Professional” tasks.
The results demonstrate the enhanced capability of Agent S in handling diverse and complex tasks more effectively than the baseline approaches.
Analysis
To demonstrate the effectiveness of individual modules of Agent S, we stratified sampled a subset of 65
instances,testsub rom the full test set for the ablation study. Considering the inference cost, we utilized GPT-4o as the
LLM backbone for all ablation studies for both the baseline and Agent S.
Learning from experience enhances the domain knowledge of GUI agents
Main results of Successful Rate (%) on the OSWorld full test set of all 369 test examples
Learning from universal experience available as web knowledge allows Agent S to make informed plans across a wide range of tasks and has the most significant impact. The learning from Narrative and Episodic memories synergies effectively with web retrieval, and the results detail how their ablation affects the agent’s ability to handle complex tasks, underscoring the value of experiential learning. These results demonstrate that each component plays a critical role in enhancing the agent’s domain knowledge. Removing all three components (w/o All) degrades the performance significantly, revealing the importance of learning from experience in the design.
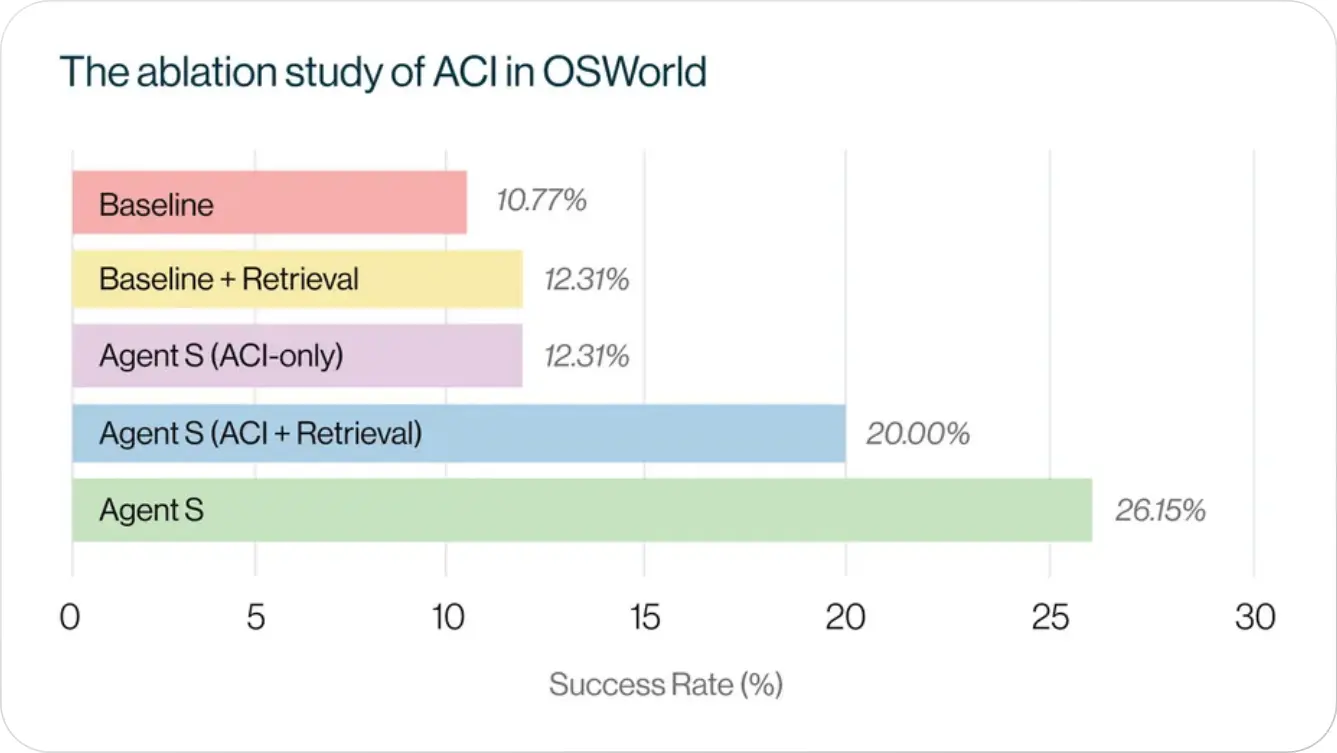

ACI elicits better reasoning abilities of LLMs and supports better agentic learning
Comparing the baseline with Agent S (ACI-only) highlights the enhanced reasoning abilities achieved by incorporating ACI. Additionally, we examined the impact of ACI on agentic learning by integrating the Experiential learning process. For the baseline, adding Experiential learning slightly improved overall performance. However, when added to Agent S (ACI-only), the performance improved significantly, demonstrating ACI's effectiveness in enhancing agentic learning
Hierarchical Planning supports
long-horizon workflows
The ACI-only + Experiential Learning setup in shows Agent S performance without Hierarchical Planning, and the observed performance drop (26.15% to 20.00%) compared to the full Agent S underscores the importance of Hierarchical Planning in modeling long-horizon workflows. The effect of hierarchical formulation becomes pronounced in the presence of Experiential learning as the Manager can generate more detailed and accurate plans in the subtask planning stage.
Exploration, Continual Memory Update and Self-Evaluator are indispensable for memory construction
Removing exploration limits memory updates to the inference phase only. Removing the continual memory update means we only use the memory obtained from the exploration phase without subsequent updates. Removing the self-evaluator involves replacing summarized experiences with the original full trajectories. The results reveal that ablating both the continual memory update and self-supervised exploration phases results in a performance drop, with the self-supervised exploration being much more impactful. The ablation of the Self-Evaluator further shows the benefits of using summarized trajectories instead of full trajectory exemplars for planning.
Generalization to Different Operating Systems
We test the Agent S framework with no modification on WindowsAgentArena, a Windows OS benchmark released contemporaneously with our work. We compare Agent S with the similar configuration with GPT-4o as the MLLM backbone, Accessibility Tree + Image as the input, and parsing with OCR. As shown in the table, Agent S outperforms the Navi agent without any adaptation to the new Windows environment.
Results of Successful Rate (%) on WindowsAgentArena using GPT-4o and Image + Accessibility Tree input on the full test set of all 154 test examples
BibTex
Ready to use your
computer in a Simular way?
Shares and organize your memory, and personalize your tasks.